TP - Python et SQLite☘
Dans ce TP, il faudra :
- utiliser des « données brutes » réunies dans un unique fichier
au format
.csv; - réaliser un programme Python qui répartit ces données dans deux tables ;
- utiliser ce programme pour générer les codes SQLite permettant de créer la base de données ;
- visualiser le travail réalisé à l'aide de DB Browser.
Source
Les données proviennent du site imdb.
Consignes
Contrairement à d'habitude, ce TP est moins « guidé ».
Les questions ont pour but de faire découvrir ou développer des outils
utiles à sa mise en oeuvre. Il faudra tirer le meilleur usage de ces outils.
Partie A - Importer les données☘
Aide sur la manipulation de fichiers en Python
Étudier à nouveau ce chapitre du cours de première.
-
Télécharger le fichier
TPB02.21_donnees.csvpuis enregistrer ce fichier dans le répertoire[B02-BDD_Relationnelle]. -
Ce fichier comporte des informations sur des films.
Dans un programme Python, copier/coller puis exécuter les instructions suivantes :1 2 3 4 5 6 7
with open('TPB02.21_donnees.csv','r',encoding='utf-8') as fichier_source: premiere_ligne = fichier_source.readline() lignes = fichier_source.readlines() print(premiere_ligne) for ligne in lignes: print(ligne) -
En déduire les attributs et le nombre d'enregistrements de cette relation.
Partie B - Formater les données☘
Afin d'éviter les doublons causés par les noms des réalisateurs, il faut
« séparer » ces données dans deux tables distinctes : Film
et Realisateur. Le schéma relationnel correspondant est :
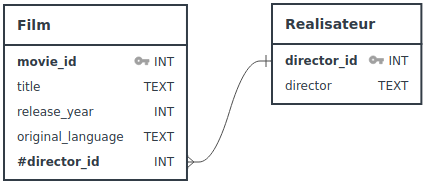
Les chaînes de caractères suivantes représentent ce schéma :
1 2 | |
-
Créer un nouveau fichier Python nommé
TPB02.21.py. -
Le fichier
TPB02.21_donnees.csvest un fichier texte. Pour traiter plus facilement ses données en Python, on souhaite traiter chaque enregistrement sous la forme d'un tableau plutôt que sous la forme d'une chaîne de caractères.-
Tester les instructions suivantes dans la console :
>>> exemple = "essai, test, exemple, " >>> exemple = exemple.rstrip(", ") >>> tab_exemple = exemple.split(",") -
En déduire le rôle des méthodes
.rstrip()et.split()ainsi que comment les utiliser. -
Définir le code de la fonction
str_to_tab()qui prend en paramètre une chaîne de caractères contenant des points-virgule.
Cette fonction supprime le caractère de saut à la ligne en fin de cette chaîne et renvoie un tableau des sous-chaînes (éventuellement vides) initialement séparées par les points-virgule.
-
-
Pour insérer les données dans la base, il faut faire attention aux données
TEXT. En effet, ces données sont encadrées par des apostrophes. Comment faire si elle contiennent elles-mêmes des apostrophes ?
Définir une fonctionnettoye()qui prend en paramètre une chaîne de caractères et qui renvoie cette chaîne si elle ne contient pas d'apostrophe ou bien cette chaîne dans laquelle chaque apostrophe est remplacé par deux apostrophes «''». Par exemple :>>> nettoye("abcd") 'abcd' >>> nettoye("aujourd'hui") "aujourd''hui" -
Parcourir les données du fichier
TPB02.21_donnees.csvet rédiger les instructions nécessaires pour obtenir :-
Un tableau (type
list) des 4759 enregistrements de la relation Film sous forme de chaînes de caractères dont voici les premières valeurs :"(8193, 'Napoleon Dynamite', 2004, 'en', 1)" "(8195, 'Ronin', 1998, 'en', 2)" "(16388, 'The Brothers McMullen', 1995, 'en', 3)" "(8197, 'Midnight in the Garden of Good and Evil', 1997, 'en', 4)" "(5, 'Four Rooms', 1995, 'en', 5)" "(8198, 'The Quiet American', 2002, 'en', 6)" "(8202, 'Æon Flux', 2005, 'en', 7)" "(11, 'Star Wars', 1977, 'en', 8)" "(12, 'Finding Nemo', 2003, 'en', 9)" "(8204, 'The Spiderwick Chronicles', 2008, 'en', 10)" -
Un tableau (type
list) des 2338 enregistrements de la relation Realisateur sous forme de chaînes de caractères dont voici les premières valeurs :"(1, 'Jared Hess')" "(2, 'John Frankenheimer')" "(3, 'Edward Burns')" "(4, 'Clint Eastwood')" "(5, 'Allison Anders')" "(6, 'Phillip Noyce')" "(7, 'Karyn Kusama')" "(8, 'George Lucas')" "(9, 'Andrew Stanton')" "(10, 'Mark Waters')"
Un algorithme possible
Pour chaque enregistrement contenu dans le fichier
TPB02.21_donnees.csv,- on transforme cet enregistrement en tableau ;
- on extrait le réalisateur de cet enregistrement ;
- on associe chaque réalisateur à un identifiant dans un dictionnaire ;
- si ce réalisateur n'était pas dans le dictionnaire, on le place dedans en l'associant à un identifiant ;
- on ajoute l'identifiant du réalisateur au tableau d'enregistrement ;
- on transforme le tableau en une chaîne de caractères placée dans un tableau regroupant tous les enregistrements de films ;
- on termine en plaçant les associations du dictionnaire dans un tableau regroupant tous les enregistrements de réalisateurs.
-
Partie C - Créer la base avec un script Python☘
Dans cette partie, importer et utiliser le module sqlite3 au début du programme
TPB02.21.py. Ce module permet à un script Python de « dialoguer »
avec un SGBD SQLite.
Description succincte de l'API sqlite3
-
Importer le module :
1
import sqlite3 -
Connexion à la base de données :
Création (dans le répertoire courant) de la base3
base = sqlite3.connect("base_test.db")base_test.dbsi elle n’existe pas encore, ouverture de cette base sinon. -
Définition d'un curseur qui permet d'agir sur la base de données :
4
curseur = base.cursor() -
Les requêtes SQL sont rédigées sous forme de chaînes de caractères.
-
Création d’une table dans la base :
Les triples guillemets permettent un passage à la ligne. Ils ont été utilisés pour mieux visualiser la commande mais il est conseillé d'utiliser des simples guillemets sans passage à la ligne...5 6 7 8
curseur.execute("""CREATE TABLE IF NOT EXISTS Utilisateur ( nom TEXT, prenom TEXT, pseudo TEXT);""" ) -
Ajout de données dans la base :
Même remarque sur les triples guillemets.10 11 12 13
curseur.execute("""INSERT INTO Utilisateur(nom, prenom, pseudo) VALUES ('Garcia', 'Serge', 'sergent_garcia'), ('De la Vega', 'Diego', 'ZoRRo'), ('McDuck', 'Scrooge', 'Picsou');""" )
-
-
Valider l’enregistrement dans la base après une (ou plusieurs) commande(s) :
15
base.commit()Attention
Sans cette instruction rien ne sera réellement enregistré dans la base de données.
-
Fermer la base :
16
base.close()
On rappelle que les chaînes de caractères suivantes représentent le schéma de la base de données :
1 2 | |
-
En utilisant l'API du module
sqlite3décrite ci-dessus, créer la base de données constituée des deux tables Film et Realisateur. -
En utilisant les variables définies (obtenues) à la fin de la partie B, insérer les données dans chacune des tables.
-
Lancer DB Browser et importez la table au format
.db.-
Vérifier que les derniers enregistrements de la table Film sont :
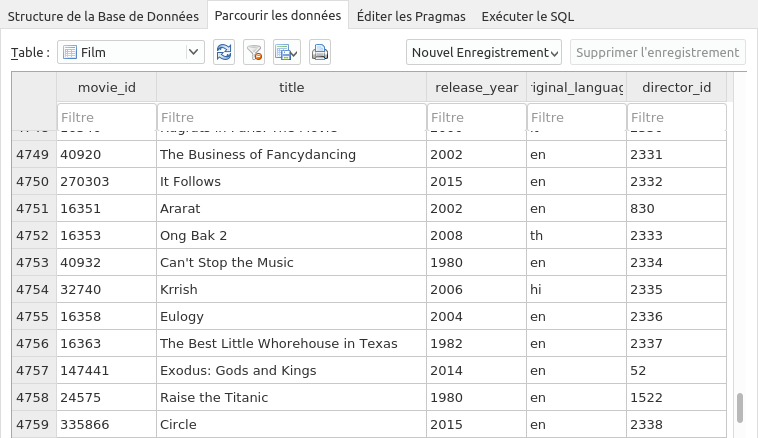
-
Vérifier que les derniers enregistrements de la table Realisateur sont :
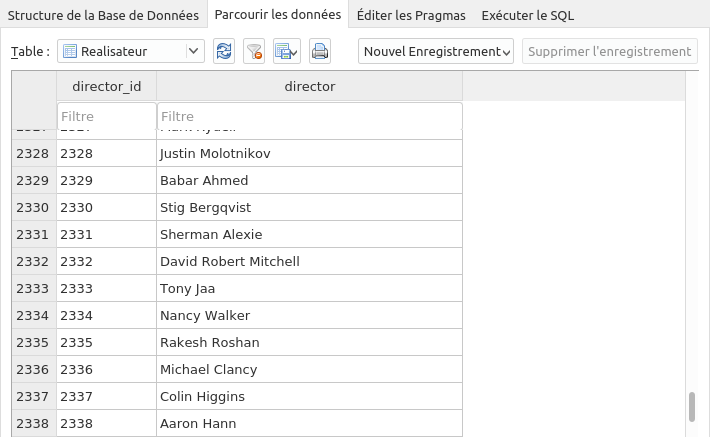
-