Exercices d'entraînement☘
Ces exercices doivent être utilisés pour vous entraîner à programmer. Ils sont généralement accompagnés d'aide et de leur solution pour vous permettre de progresser.
Avant de vous précipiter sur ces solutions dès la première difficulté, n'oubliez pas les conseils suivants :
- Avez-vous bien fait un schéma au brouillon pour visualiser le problème posé ?
- Avez-vous essayé de rédiger un algorithme en français, avec vos propres mots, avant de vous lancer dans la programmation sur machine ?
- Avez-vous utilisé des affichages intermédiaires, des
print(), pour visualiser au fur et à mesure le contenu des variables ? - Avez-vous testé le programme avec les propositions de tests donnés dans l'exercice ?
- Avez-vous testé le programme avec de nouveaux tests, différents de ceux proposés ?
Rappels
- Chaque programme Python doit être sauvegardé sous forme de fichier texte avec l'extension
.py.
Enregistrez ce fichier dans le dossier[B04-Dictionnaire]avec le nom onné à l'exercice :ProgB04.51.py,ProgB04.52.py, etc... - Pour exécuter ce programme, il suffit de le sauvegarder puis d'appuyer sur la touche
[F5]. - Le programme principal doit contenir un appel au module
doctest:##----- Programme principal et tests -----## if __name__ == '__main__': import doctest doctest.testmod()
ProgB04.51☘
On dispose d'un tableau de prénoms :
1 2 3 4 5 6 | |
Complétez la définition de la fonction compte_occurences() qui prend
en paramètre un tel tableau et qui renvoye un dictionnaire dont les
clefs sont les lettres présentes dans les prénoms et dont les valeurs
sont le nombre d'occurrences de ces lettres dans l'ensemble des prénoms
du tableau.
8 9 10 11 12 13 14 15 | |
Exemple
Le tableau prenoms ci-dessus contient trois prénoms commençant
par la lettre 'L' :
>>> dico = compte_occurrences(prenoms)
>>> dico['L']
3
Une solution
8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
ProgB04.52 - Calcul fractionnaire☘
On représente des fractions à l'aide de dictionnaires :
{'numérateur': ..., 'dénominateur': ...}.
-
Complétez la définition de la fonction
somme():1 2 3 4 5 6 7 8 9 10 11
def somme(p, q): """ p - dict, dictionnaire représentant une fraction q - dict, dictionnaire représentant une fraction Sortie: dict - dictionnaire représentant la fraction p+q >>> a = {'numérateur': 1, 'dénominateur': 2} >>> b = {'numérateur': 2, 'dénominateur': 3} >>> somme(a, b) {'numérateur': 7, 'dénominateur': 6} """Une solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14
def somme(p, q): """ p - dict, dictionnaire représentant une fraction q - dict, dictionnaire représentant une fraction Sortie: dict - dictionnaire représentant la fraction p+q >>> a = {'numérateur': 1, 'dénominateur': 2} >>> b = {'numérateur': 2, 'dénominateur': 3} >>> somme(a, b) {'numérateur': 7, 'dénominateur': 6} """ numerateur = p['numérateur'] * q['dénominateur'] + p['dénominateur'] * q['numérateur'] denominateur = p['dénominateur'] * q['dénominateur'] return {'numérateur': numerateur, 'dénominateur': denominateur} -
Complétez la définition de la fonction
reduit():3 4 5 6 7 8 9 10 11 12 13 14
def reduit(p): """ p - dict, dictionnaire représentant une fraction Sortie: dict, dictionnaire représentant la fraction p sous sa forme irréductible >>> a = {'numérateur': 6, 'dénominateur': 8} >>> reduit(a) {'numérateur': 3, 'dénominateur': 4} >>> b = {'numérateur': 42, 'dénominateur': 66} >>> reduit(b) {'numérateur': 7, 'dénominateur': 11} """Une piste
On pourra utiliser la fonction
gcd()du modulemathqui renvoie le PGCD des deux nombres entiers passés en paramètre.
1
from math import gcdUne solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
from math import gcd def reduit(p): """ p - dict, dictionnaire représentant une fraction Sortie: dict, dictionnaire représentant la fraction p sous sa forme irréductible >>> a = {'numérateur': 6, 'dénominateur': 8} >>> reduit(a) {'numérateur': 3, 'dénominateur': 4} >>> b = {'numérateur': 42, 'dénominateur': 66} >>> reduit(b) {'numérateur': 7, 'dénominateur': 11} """ num = p['numérateur'] den = p['dénominateur'] d = gcd(num, den) return {'numérateur': num//d, 'dénominateur': den//d}
ProgB04.53 - Arborescence☘
On représente une arborescence de dossiers et fichiers à l'aide d'un tableau de dictionnaires.
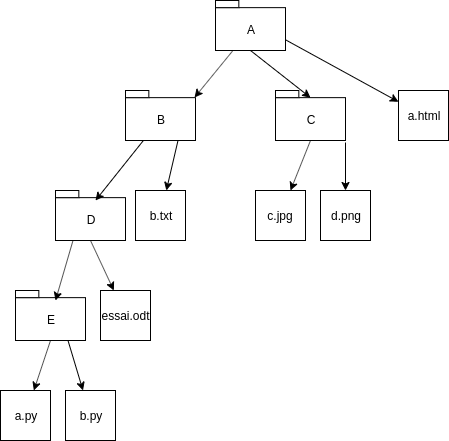
L'arborescence ci-dessus est ainsi représentée par le tableau :
14 15 16 17 18 19 20 21 22 23 24 25 26 | |
-
Complétez la définition de la fonction
frere()en respectant ses spécifications :1 2 3 4 5 6 7 8
def frere(tab_arbo, i1, i2): """ tab_arbo - list, tableau contenant une structure arborescente comme dans l'exemple. i1, i2 - int, entiers tels que 0 <= i1 < len(tab_arbo) et 0 <= i2 < len(tab_arbo) Sortie: bool - True si les éléments d'indices i1 et i2 sont frères (c'est-à-dire ont le même père dans l'arborescence). """Une solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
def frere(tab_arbo, i1, i2): """ tab_arbo - list, tableau contenant une structure arborescente comme dans l'exemple. i1, i2 - int, entiers tels que 0 <= i1 < len(tab_arbo) et 0 <= i2 < len(tab_arbo) Sortie: bool - True si les éléments d'indices i1 et i2 sont frères (c'est-à-dire ont le même père dans l'arborescence). """ noeud1 = tab_arbo[i1] noeud2 = tab_arbo[i2] return noeud1['père'] == noeud2['père'] ##----- Programme principal -----## arbo = [ {'nom': 'A', 'type': 'dossier', 'père': None}, {'nom': 'B', 'type': 'dossier', 'père': 'A'}, {'nom': 'C', 'type': 'dossier', 'père': 'A'}, {'nom': 'D', 'type': 'dossier', 'père': 'B'}, {'nom': 'E', 'type': 'dossier', 'père': 'D'}, {'nom': 'a', 'type': 'fichier', 'père': 'A', 'extension': 'html'}, {'nom': 'b', 'type': 'fichier', 'père': 'B', 'extension': 'txt'}, {'nom': 'c', 'type': 'fichier', 'père': 'C', 'extension': 'jpg'}, {'nom': 'd', 'type': 'fichier', 'père': 'C', 'extension': 'png'}, {'nom': 'essai', 'type': 'fichier', 'père': 'D', 'extension': 'odt'}, {'nom': 'a', 'type': 'fichier', 'père': 'E', 'extension': 'py'}, {'nom': 'b', 'type': 'fichier', 'père': 'E', 'extension': 'py'}] # test: print(frere(arbo, 1, 2)) print(frere(arbo, 1, 3)) -
Compléter la définition de la fonction
recherche_fils()en respectant ses spécifications :1 2 3 4 5 6 7 8 9 10 11 12
def recherche_fils(tab_arbo, indice): """ tab_arbo - list, tableau contenant une structure arborescente comme dans l'exemple. indice - int, entier tel que 0 <= indice < len(tab_arbo) Sortie: None - complète tab_arbo[indice] par l'association 'fils': chaine des noms des fils si tab_arbo[indice] est de type dossier. Par exemple rechercheFils(arbo, 0) modifiera arbo[0] en {'nom': 'A', 'type': 'dossier', 'père': None, 'fils': 'B, C, a.html'}. L'extension est inscrite dans la chaîne en cas de fichier. """Une piste
Vous pouvez programmer une fonction intermédiaire nommée
copie_sans_derniers_caracteres()qui aura pour rôle de renvoyer la chaîne de caractères passée en paramètre, mais privée de ses deux derniers caractères.Une solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58
def copie_sans_derniers_caracteres(chaine): """ chaine - str, chaine de caractères Sortie: str - la chaine privée de ses deux derniers caractères >>> copie_sans_derniers_caracteres("as, tr, ap, i,") 'as, tr, ap, ' >>> copie_sans_derniers_caracteres("bah ?") 'bah' """ result = '' for i in range(len(chaine)-2): result = result + chaine[i] return result def recherche_fils(tab_arbo, indice): """ tab_arbo - list, tableau contenant une structure arborescente comme dans l'exemple. indice - int, entier tel que 0 <= indice < len(tab_arbo) Sortie: None - complète tab_arbo[indice] par l'association 'fils': chaine des noms des fils si tab_arbo[indice] est de type dossier. Par exemple rechercheFils(arbo, 0) modifiera arbo[0] en {'nom': 'A', 'type': 'dossier', 'père': None, 'fils': 'B, C, a.html'}. L'extension est inscrite dans la chaîne en cas de fichier. """ cible = tab_arbo[indice] if cible['type'] == 'dossier': cible['fils'] = '' for noeud in tab_arbo: if noeud['père'] == cible['nom']: if 'extension' in noeud.keys(): cible['fils'] = cible['fils'] + noeud['nom'] + '.' + noeud['extension'] + ', ' else: cible['fils'] = cible['fils'] + noeud['nom'] + ', ' # on efface la virgule et l'espace de trop en fin de chaîne: cible['fils'] = copie_sans_derniers_caracteres(cible['fils']) ##----- Programme principal -----## arbo = [ {'nom': 'A', 'type': 'dossier', 'père': None}, {'nom': 'B', 'type': 'dossier', 'père': 'A'}, {'nom': 'C', 'type': 'dossier', 'père': 'A'}, {'nom': 'D', 'type': 'dossier', 'père': 'B'}, {'nom': 'E', 'type': 'dossier', 'père': 'D'}, {'nom': 'a', 'type': 'fichier', 'père': 'A', 'extension': 'html'}, {'nom': 'b', 'type': 'fichier', 'père': 'B', 'extension': 'txt'}, {'nom': 'c', 'type': 'fichier', 'père': 'C', 'extension': 'jpg'}, {'nom': 'd', 'type': 'fichier', 'père': 'C', 'extension': 'png'}, {'nom': 'essai', 'type': 'fichier', 'père': 'D', 'extension': 'odt'}, {'nom': 'a', 'type': 'fichier', 'père': 'E', 'extension': 'py'}, {'nom': 'b', 'type': 'fichier', 'père': 'E', 'extension': 'py'}] # test: recherche_fils(arbo, 0) for noeud in arbo: print(noeud)Complément
En Python, la fonction
copie_sans_derniers_caracteres()peut être redéfinie de façon plus brève comme suit :1 2 3 4 5 6 7 8 9 10 11
def copie_sans_derniers_caracteres(chaine): """ chaine - chaine de caractères Sortie: chaine - la chaine privée de ses deux derniers caractères >>> copie_sans_derniers_caracteres("as, tr, ap, i,") 'as, tr, ap, ' >>> copie_sans_derniers_caracteres("bah ?") 'bah' """ return chaine[:-2]Vous pouvez travailler cette page pour en savoir plus sur cette notation qui n'est pas au programme de 1ère NSI.
-
Définissez ensuite une fonction qui complète tous les noeuds dossiers du tableau par cet attribut
'fils'.Une solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67
def copie_sans_derniers_caracteres(chaine): """ chaine - str, chaine de caractères Sortie: str - la chaine privée de ses deux derniers caractères >>> copie_sans_derniers_caracteres("as, tr, ap, i,") 'as, tr, ap, ' >>> copie_sans_derniers_caracteres("bah ?") 'bah' """ result = '' for i in range(len(chaine)-2): result = result + chaine[i] return result def recherche_fils(tab_arbo, indice): """ tab_arbo - list, tableau contenant une structure arborescente comme dans l'exemple. indice - int, entier tel que 0 <= indice < len(tab_arbo) Sortie: None - complète tab_arbo[indice] par l'association 'fils': chaine des noms des fils si tab_arbo[indice] est de type dossier. Par exemple rechercheFils(arbo, 0) modifiera arbo[0] en {'nom': 'A', 'type': 'dossier', 'père': None, 'fils': 'B, C, a.html'}. L'extension est inscrite dans la chaîne en cas de fichier. """ cible = tab_arbo[indice] if cible['type'] == 'dossier': cible['fils'] = '' for noeud in tab_arbo: if noeud['père'] == cible['nom']: if 'extension' in noeud.keys(): cible['fils'] = cible['fils'] + noeud['nom'] + '.' + noeud['extension'] + ', ' else: cible['fils'] = cible['fils'] + noeud['nom'] + ', ' # on efface la virgule et l'espace de trop en fin de chaîne: cible['fils'] = copie_sans_derniers_caracteres(cible['fils']) def complete_fils(tab_arbo): """ tab_arbo - list, tableau contenant une structure arborescente comme dans l'exemple. Sortie: None - complète chaque noeud dossier par le champ'fils'. """ for indice in range(len(tab_arbo)): recherche_fils(tab_arbo, indice) ##----- Programme principal -----## arbo = [ {'nom': 'A', 'type': 'dossier', 'père': None}, {'nom': 'B', 'type': 'dossier', 'père': 'A'}, {'nom': 'C', 'type': 'dossier', 'père': 'A'}, {'nom': 'D', 'type': 'dossier', 'père': 'B'}, {'nom': 'E', 'type': 'dossier', 'père': 'D'}, {'nom': 'a', 'type': 'fichier', 'père': 'A', 'extension': 'html'}, {'nom': 'b', 'type': 'fichier', 'père': 'B', 'extension': 'txt'}, {'nom': 'c', 'type': 'fichier', 'père': 'C', 'extension': 'jpg'}, {'nom': 'd', 'type': 'fichier', 'père': 'C', 'extension': 'png'}, {'nom': 'essai', 'type': 'fichier', 'père': 'D', 'extension': 'odt'}, {'nom': 'a', 'type': 'fichier', 'père': 'E', 'extension': 'py'}, {'nom': 'b', 'type': 'fichier', 'père': 'E', 'extension': 'py'}] # test: complete_fils(arbo) for noeud in arbo: print(noeud) -
Expliquez pourquoi la représentation de l'arborescence choisie n'est pas vraiment pertinente.
Une réponse
On peut ajouter un dossier nommé
Ecomme fils deC, et contenant un fichiera.pyet un fichierb.py. Ces deux fichiersa.pyetb.pyont alors exactement les mêmes attributs que les deux fichiersa.pyetb.pydéjà présents, ils ne peuvent donc plus être distingués !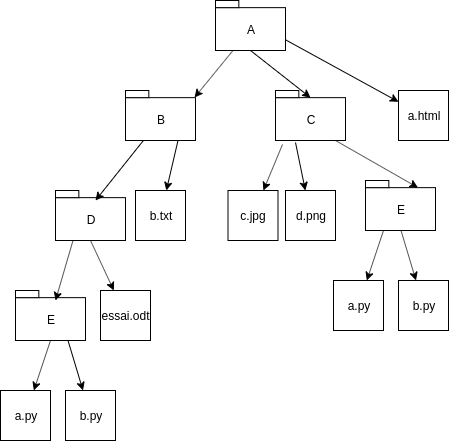
Pour pallier à ce problème, on pourrait choisir comme nom les chemins absolus (depuis la racine). Ainsi, le fichier
essai.odtse nommerait/A/B/D/essai.odt.
On peut ainsi distinguer le fichier/A/B/D/E/a.pydu fichier/A/C/E/a.py.